A note on data mining
Introduction
Let's go back to the crime data from the city of Los Angeles
- You notice that the data contains a lot of fields, and it is not obvious what they represent
- I used the dataset for this paper A spatiotemporal analysis of the impact of COVID-19 on child abuse and neglect in the city of Los Angeles, California - ScienceDirect
- Let's take a look at the code book
- There is an interesting field called mo which in the law stands for modus operandi
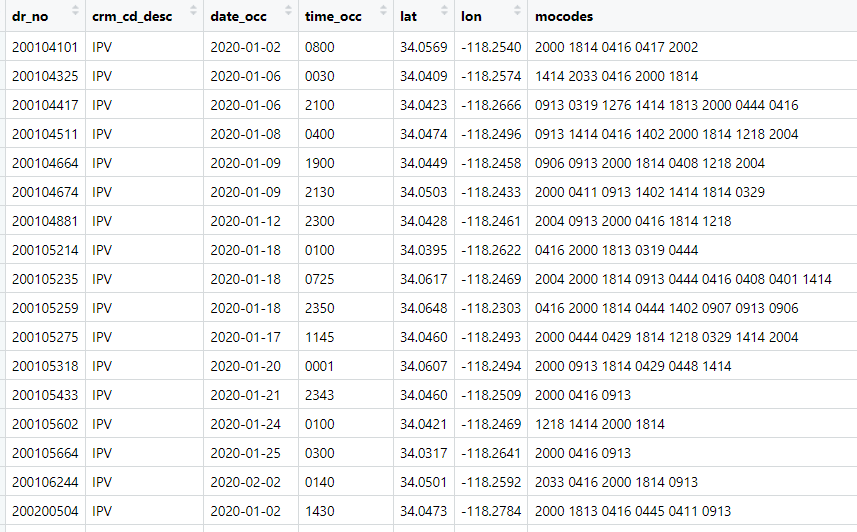
- Notice that this field possible has a ton of data that is all but ignored because people don't pay careful attention
- Below I show you how I used R to create 10 additional fields of data from the mo field
library(RSocrata)
base_url = "https://data.lacity.org/resource/2nrs-mtv8.json?" #this is the dataset 2020 to present
my_token <- "w0BkWUPZYzjQRwNEVX8KEijw4"
lacity_data <- read.socrata(base_url, my_token)
glimpse(lacity_data)
ipv_crimes_in_la <- lacity_data %>%
mutate(vict_age = as.numeric(vict_age)) %>%
filter(str_detect(crm_cd_desc, "INTIMATE PARTNER"),
str_detect(premis_desc, "MOTORHOME|GROUP HOME|MOTEL|DWELLING|RESIDENTIAL|HOUSING")) %>%
mutate(crm_cd_desc = str_replace(crm_cd_desc, ".*INTIMATE PARTNER.*", "IPV"))%>%
select("dr_no", "crm_cd_desc", "date_occ", "time_occ", "lat", "lon", "mocodes","area_name", "vict_age", "vict_sex", "vict_descent", "premis_desc", "weapon_desc", "status_desc")
glimpse(ipv_crimes_in_la)
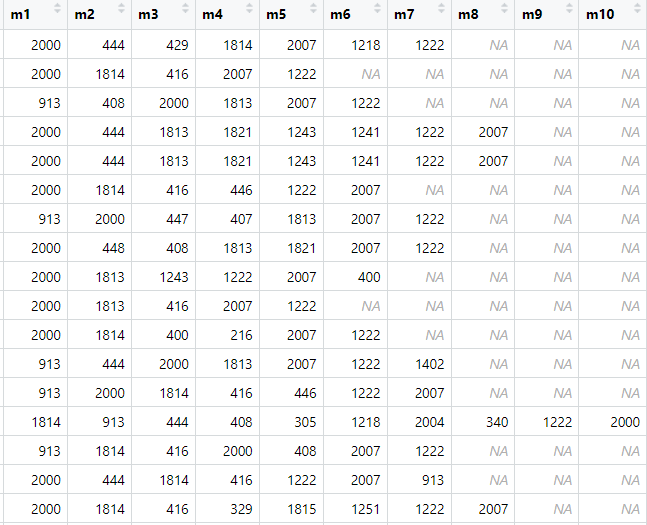
ipv_crimes_in_la$mo <- ipv_crimes_in_la$mocodes
ipv_crime_mo <- separate(data = ipv_crimes_in_la, col = mocodes, into =
c("m1", "m2", "m3", "m4", "m5", "m6", "m7", "m8", "m9", "m10"),
sep = " ")
#makes all "m" variables numeric at once
ipv_crime_mo[,7:16] <- sapply(ipv_crime_mo[,7:16],as.numeric)
glimpse(ipv_crime_mo)
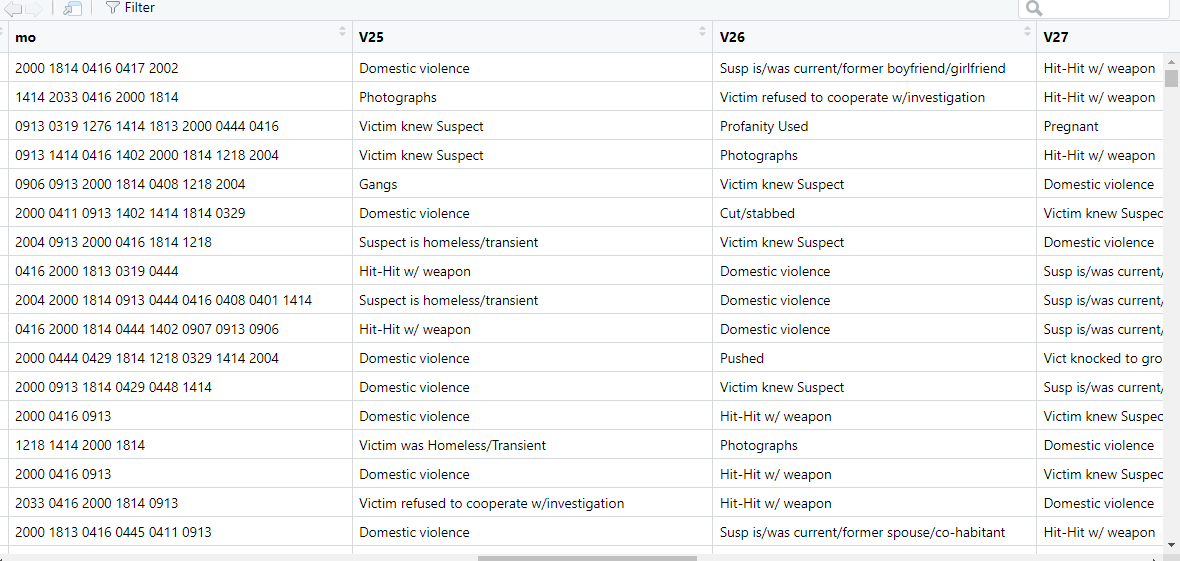
tbl_lookup<-read.csv("C:/Users/barboza-salerno.1/OneDrive - The Ohio State University/Desktop/Research/LA County/MO_CODES_Numerical_20180627.csv")
names(tbl_lookup)[1] <- "id"
for (i in 1:10){
ipv_crime_mo[,(length(ipv_crime_mo)+1)] = tbl_lookup[match(ipv_crime_mo[,(i+6)], tbl_lookup$id), "descript"]
}
library(writexl)
write_xlsx(ipv_crime_mo, "ipv_crime_mo.xlsx")
-
First, we separate the mo column into multiple colums
-
Then I create a lookup table based on this file of mo codes and descriptions
-
Then I replaced the codes with the text in the data
-
Now I can filter the data for crimes involving any number of modus operandi, for example, the code below filters all IPV crimes that involved "homosexuals"
homosexual_data <- ipv_crime_mo %>%
filter_at(.vars = vars(V25, V26, V27, V28, V29, V30, V31, V32, V33, V34),
.vars_predicate = any_vars(str_detect(. , "Homo")))